这里用到 QueryList这个第三方插件,安装要求
php>=7.1
composer 安装
composer require jaeger/querylist
或者直接下载
开箱即用:https://pan.baidu.com/s/1QPMUalL5HcVJ4L7zUY0LMg
require_once app()->getRootPath()."extend/queryList/autoload.php";// 引入插件
$QueryList=new \QL\QueryList();
$url ='xxxxxxxxxxxxxxxxxxx';//需要获取小说的链接
$rt = [];
//根据页面获取书籍信息
$rules = [
'title' => ['.t>a','text'], // 获取小说名称
'link' => ['.n>a','href'], // 获取小说的链接
'author' => ['.author>a','text'], //获取小说的作者
'status' => ['.abover>span','text'], //获取小说的状态
];
$range = '.ul_m_list li'; // 切片选择器
//encoding('UTF-8','GB2312') 转码
$rt = $QueryList->get($url)->rules($rules)->range($range)->removeHead()->encoding('UTF-8','GB2312')->query()->getData();
dump($rt->all());exit;
根据网站的机构去获取书籍内容,比如这个网站

书名是在class .t>a 下面的 ,链接是在class .n>a 下面的
range :切片选择工具 就是书籍循环的外包结构 可以将书籍分割成一个一个的数组
remove:可以将内容中的部分内容过滤掉
$html =<<<STR
<div id="content">
<span class="tt">作者:xxx</span>
这是正文内容段落1.....
<span>这是正文内容段落2</span>
<p>这是正文内容段落3......</p>
<span>这是广告</span>
<p>这是版权声明!</p>
</div>
STR;
$rules = [
'content' => ['#content','html']
];
$rt = QueryList::rules($rules)
->html($html)
->query()
->getData(function($item){
$ql = QueryList::html($item['content']);
$ql->find('.tt,span:last,p:last')->remove();
$item['content'] = $ql->find('')->html();
return $item;
});
Array
(
[0] => Array
(
[content] => 这是正文内容段落1.....
<span>这是正文内容段落2</span>
<p>这是正文内容段落3......</p>
)
)
print_r($rt->all());
$rt->find('.tt,span:last,p:last')->remove();
encoding:作用于内容的转码,原来的网站'GB2312' 获取的内容会出现乱码,需要将他转换成‘utf-8‘。

$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = [
'content' => ['div>p:last','text']
];
$data = QueryList::html($html)->rules($rule)
->encoding('UTF-8','GB2312')->query()->getData();
设置输入输出编码,并移除html头部
如果设置输入输出参数仍然无法解决乱码,那就使用 removeHead()方法移除html头部
removeHead:过滤掉头部
这样我们就将这个页面的书籍列表都获取下来

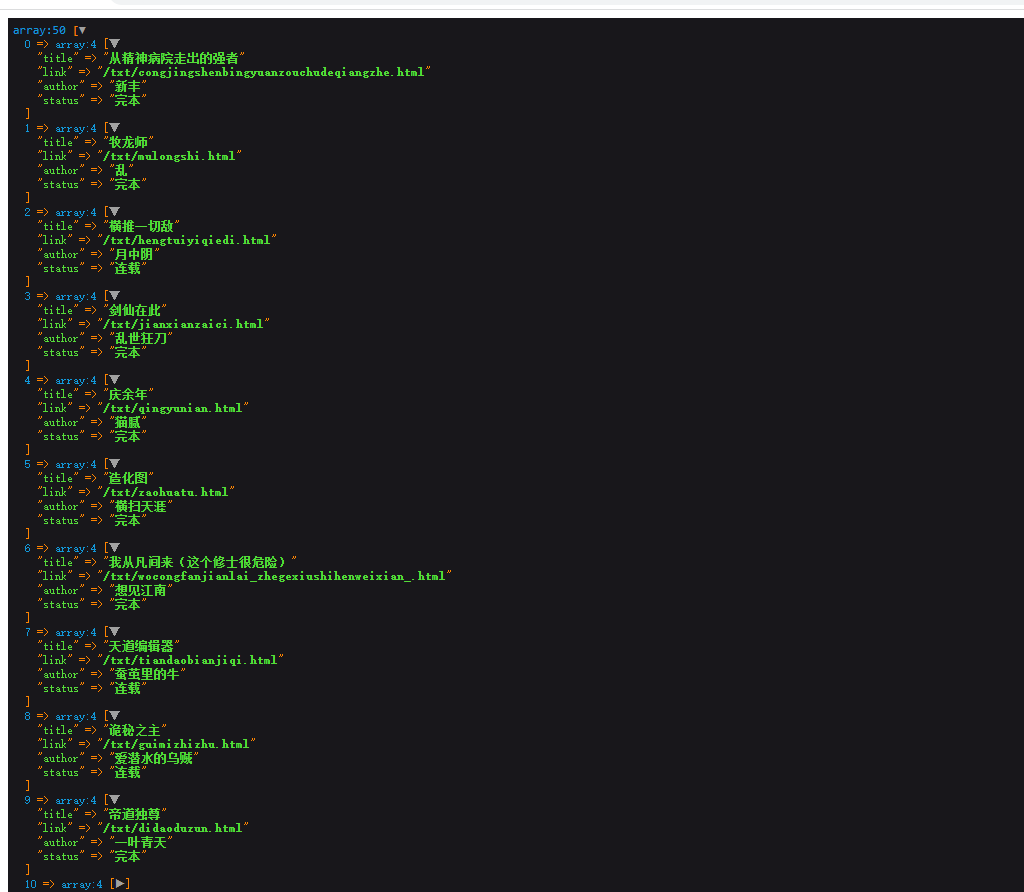

让后通过循环去获取分页的数据,根据书籍链接获取书籍的章节,封面等其他数据,最后通过章节链接获取到小说内容。





